|
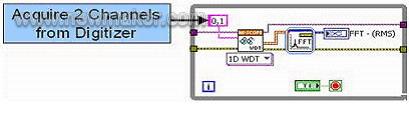
多核处理器环境下的编程挑战 摩尔定律问世40余年来,人们业已看到半导体芯片制造工艺水平以一种令人目眩的速度在提高,Intel微处理器的最高主频甚至超过了4G。虽然主频的提升一定程度上提高了程序运行效率,但越来越多的问题也随之出现,耗电、散热都成为阻碍设计的瓶颈所在,芯片成本也相应提高。当单独依靠提高主频已不能实现性能的高效率时,双核乃至多核成为了提高性能的唯一出路。随着AMD率先打破摩尔定律、终结频率游戏后,Intel和AMD都开始逐步推出了基于双核、四核甚至八核的处理器,工程师们逐渐投入到基于多核处理器的新型应用开发中去时,大家开始发现,借助这些新的多核处理器,并在应用开发中利用并行编程技术,可以实现最佳的性能和最大的吞吐量,大大提高应用程序的运行效率。 然而,业界专家们也同时认识到,对于实际的编程应用,多核处理器的并行编程却是一个巨大的挑战。比尔盖茨是这样论述的: “要想充分利用并行工作的处理器的威力,…软件必须能够处理并发性问题。但正如任何一位编写过多线程代码的开发者告诉你的那样,这是编程领域最艰巨的任务之一。” 专业研发、生产、销售:测漏机,检漏机,试漏机,测漏仪,塑料瓶装袋机,垫片冲裁入盖机,客服热线:13929416960. 比如用C++写一个多线程的程序,程序员必须要非常熟悉 C++,了解如何将C++程序分成多个线程和并在各个线程间进行任务调度,此外还要了解 Windows 多线程的机制,熟悉 Windows API 的调用方法和MFC 的架构等等。在 C++ 上调试多线程程序,更是被很多程序员视为噩梦。 所以,对于测试测量行业的工程师来说,在传统开发环境下要想获得多核下的效率提升意味着大量而复杂的多线程编程任务,而使得工程师脱离了自动化测试及其信号处理任务本身,于是,要想在当前的多核机器上充分利用其架构和并行运算的优势,反而成为工程师们“不可能”完成的任务。 LabVIEW降低并行编程的复杂性,快速开发并行构架的信号处理应用 幸运的是,NI LabVIEW图形化开发平台为我们提供了一个理想的多核处理器编程环境。作为一种并行结构的编程语言,LabVIEW能将多个并列的程序分支自动分配成多个线程并分派到各个处理核上,让一些计算量较大的数学运算或信号处理应用得以提高运行效率,并获取最佳性能。 我们以自动化测试中最常见的多通道信号处理分析为例。由于多通道中的频率分析是一项占用处理器资源较多的操作,如果能够让程序并行地将每个通道的信号处理任务分配至多个处理器核,对于提高程序执行速度来说,就显得尤为重要。而目前,从LabVIEW编程人员的角度来看,要想获得这一原本“不可能”的技术优势,唯一需要改变的只是算法结构的细微调整,而并不需要复杂且耗时耗力的代码重建工作。 以双通道采样为例,我们需要分别对高速数字化仪的两个通道上的数据进行快速傅立叶变换(FFT)。假设我们采用的高速数字化仪的两个通道均以100 MS/s采样率采集信号并实时分析。首先,我们来看LabVIEW中对于这一操作的传统顺序编程模型。
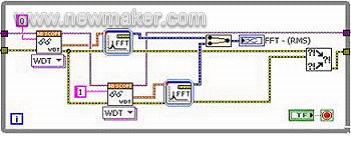
实际上,两个通道的FFT运算相互独立,如果程序能够将两个FFT自动分配到一台双核机器上的的两个CPU上,那么理论上程序的运行效率将提高一倍。在LabVIEW的图形化编程平台上,情况正是如此,我们可以通过并行化处理这两个通道来真正提高算法性能。图2表示了一种采用并行结构的LabVIEW代码,从图形化编程的角度来看,仅仅是增加了一路并行的FFT函数而已。
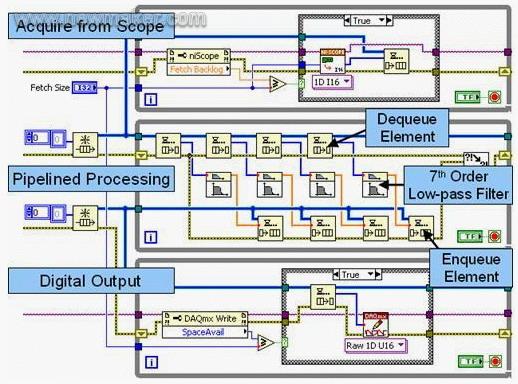
程序性能的进一步优化 LabVIEW并行的信号处理算法不仅帮助工程师提高程序性能,而且可以更清楚的划分多个处理器核在项目中的不同用途。比如,将控制采样输入,显示输出和信号分析的模块独立分开。 以HIL(Hareware-in-the-loop)或在线信号处理应用为例。首先,使用高速数字化仪或高速数字I/O模块来采集信号,并在软件中执行数字信号处理算法。然后,通过另一个模块化仪器生成结果。常见HIL应用包括在线数字信号处理(如滤波、插值等等)、传感器仿真和定制组件模拟等等。 一般来说,HIL可以使用两种基本的编程结构来完成,单循环结构和带有队列的流水线式多循环结构。单循环结构实现简单,对于小数据块具有较低时延,但单循环结构受限于各个环节的顺序结构而无法实现并发性,例如,由于处理器只能执行一个函数,在处理数据的同时就无法执行仪器IO,所以单循环结构无法有效利用多核CPU的优势。相比之下,多循环结构则能够更好的利用到多核处理器,从而支持高得多的吞吐量。 对于一项多循环结构的HIL应用来说,可以通过三个独立的while循环和两个队列结构,实现其间的数据传递。在此情况下,第一个循环从仪器采集数据,第二个循环专门执行信号处理分析,而第三个循环将数据写入到另一台仪器。这样的处理方式,也被称之为流水线式信号处理(pipeline)。
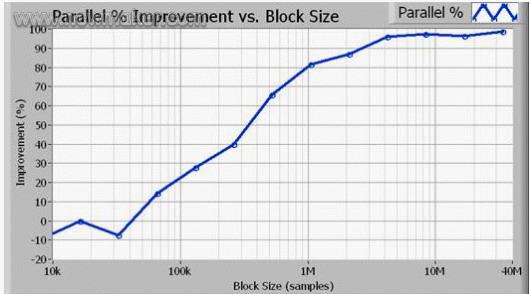
并行处理算法改善了多核CPU的处理器利用率。事实上,总吞吐量取决于两个因素,处理器利用率和总线传输速度。通常,CPU和数据总线在处理大数据块时工作效率最高。而且,我们可以进一步使用具有更快传输速度的PXI(PCI) Express仪器,来减小数据传输时间。 利用NI强大的并行性计算的优势以及PCIe高速数据流传输加上Intel的多核技术,在DELL的PowerEdge 2950八核处理器上,以10KHz(2.56MB/s)的速率同步采样并处理128个通道的数据,NI帮助ASDEX Tokamak——德国最先进的核聚变装置,完成了“不可能完成的任务”——为了保证Tokamak装置中等离子体的高速稳定的运转,将其装置外壁上的88个磁感应器上的大量数据转换成64*128个点格上的偏微分方程组,并同时在短短的1ms内完成了整个计算过程! 正如德国开发负责人Dr. Louis Giannone所说的: “利用LabVIEW编程所完成的并行化应用控制,我们在8核机器上将速度提高了5倍,使得我们成功达到1ms闭环控制速率的要求!”。 |
语言版本选择: